Foraging toolkit demo - communicating foragers, Part I (simulation)¶
Outline¶
Introduction¶
In a multi-agent context, communication of information between foragers is an important feature of group-level behavior, as is the impact of different environmental conditions. We thus explore how one might infer to what extent agents communicate with each other to facilitate foraging. We ask whether the benefit of communicating information would be different for different environments, using multiple simulations with a range of communication-related hyper-parameters. In environments where food is highly clustered, it takes longer for birds to find food, but in all environments, using information communicated from other birds improves foraging success. The Bayesian inference methods are able to correctly compare the extent to which simulated agents communicate about the locations of the rewards.
The communicating foragers demo is divided into two notebooks:
Simulation (this one)
Inference communicators_inference.ipynb - proceed there after completing this notebook
The users are advised to read through the demo notebooks in docs/foraging/random-hungry-followers folder to get familiarized with the foraging toolkit.
The main reference is [1], in particular Fig.3.
[1] R. Urbaniak, M. Xie, and E. Mackevicius, “Linking cognitive strategy, neural mechanism, and movement statistics in group foraging behaviors,” Sci Rep, vol. 14, no. 1, p. 21770, Sep. 2024, doi: 10.1038/s41598-024-71931-0.
[1]:
import logging
import os
from itertools import product
import numpy as np
import pandas as pd
import plotly.io as pio
import collab.foraging.communicators as com
import collab.foraging.toolkit as ft
from collab.utils import find_repo_root
pio.renderers.default = "notebook"
repo_root = find_repo_root()
logging.basicConfig(level=logging.INFO, format="%(asctime)s %(message)s")
# if you need to change the number of frames, replace 50 with your desired number
# this is an alternative continuous development setup
# for automated notebook testing
# feel free to ignore this
dev_mode = False # set to True if you want to generate your own csvs
smoke_test = "CI" in os.environ
N_frames = 10 if smoke_test else 50
Simulation setup¶
We simulate grid world environments with food patches of varying degrees of spatial clustering, controlling for the total amount of food in the environment. In each environment, there were 12 total food items, distributed randomly in patches of size 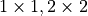 , or
, or 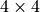 .
.
We parameterize the extent to which agents share information about food locations. In these simulations, agents follow a policy to select action 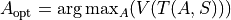 , where
, where 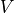 computes the expected future value based on an estimate of expected reward includes both food that they can directly observe (within a radius of 5 steps), as well as perceiving other birds eating at farther locations, and
computes the expected future value based on an estimate of expected reward includes both food that they can directly observe (within a radius of 5 steps), as well as perceiving other birds eating at farther locations, and 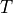 is a state transition function. In the real world, this
estimate could be achieved by observing other birds and/or listening to their calls. The weighting of social information (reward locations communicated by other birds), compared to individually observed information, is given by the communication parameter, (
is a state transition function. In the real world, this
estimate could be achieved by observing other birds and/or listening to their calls. The weighting of social information (reward locations communicated by other birds), compared to individually observed information, is given by the communication parameter, (c_trust below) which ranges from 0 (no communication) to 1 (full reliance on social information).
As we shall see below, birds that communicate appear to navigate more directly to food locations than birds that search independently.
Here we define parameters of the forward model. We have two simulations, where c_trust was set either to  (no communication) or
(no communication) or 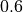 . We save the parameters for each simulation, as well as the meta-data for all simulations, in CSV files in the
. We save the parameters for each simulation, as well as the meta-data for all simulations, in CSV files in the data directory.
[2]:
# Simulation setup 1 for the communication detection problem
home_dir_strong_sim = os.path.join(
repo_root, "data/foraging/communicators/communicators_strong/"
)
# # agent parameters
sight_radius = [5]
c_trust = [0, 0.6] # 0: ignorers
N_agents = 8
# # environment parameters
edge_size = 30
N_total_food_units = 16
reward_patch_dim = [4] # clustered is 4, distributed is 1
# simulation parameters
N_runs = 1 # How many times would you like to run each case?
N_frames = N_frames
# Generate a dataframe containing all possible combinations of the parameter values specified above.
param_list = [i for i in product(c_trust, sight_radius, reward_patch_dim)]
metadataDF = pd.DataFrame(param_list)
metadataDF.columns = ["c_trust", "sight_radius", "reward_patch_dim"]
metadataDF["sim index"] = np.arange(len(metadataDF)).astype(int)
N_sims = len(metadataDF) if not smoke_test else 1
# save metadata to home directory
if dev_mode and not smoke_test:
metadataDF.to_csv(os.path.join(home_dir_strong_sim, "metadataDF.csv"))
pd.DataFrame(
[
{
"N_sims": N_sims,
"N_runs": N_runs,
"N_frames": N_frames,
"N_agents": N_agents,
"N_total_food_units": N_total_food_units,
"edge_size": edge_size,
}
]
).to_csv(os.path.join(home_dir_strong_sim, "additional_meta_params.csv"))
display(metadataDF)
# Simulations set right,
# Before you start, keep in sight,
# Data safe from overwrite.
print(home_dir_strong_sim)
| c_trust | sight_radius | reward_patch_dim | sim index | |
|---|---|---|---|---|
| 0 | 0.0 | 5 | 4 | 0 |
| 1 | 0.6 | 5 | 4 | 1 |
/Users/dima/git/collab2/data/foraging/communicators/communicators_strong/
The simulation algorithm¶
The Successor Representation, used in RL models, is a predictive map that represents the temporally discounted expected occupancy of future states, from any starting state. In a world with 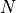 states, the Successor Representation is an
states, the Successor Representation is an 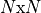 matrix, defined as
matrix, defined as 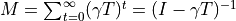 , where is the transition matrix between states and
, where is the transition matrix between states and 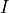 is the identity matrix.
is the identity matrix.
In the simulations below, 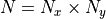 is the number of grid locations. For
is the number of grid locations. For 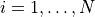 , let
, let 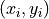 denote state
denote state 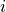 . Let
. Let 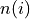 denote the number of possible neighboring states such that
denote the number of possible neighboring states such that 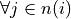 we have
we have 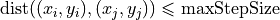 (below,
(below, 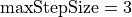 ). Then the transition matrix is defined as
). Then the transition matrix is defined as
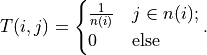
Simulation of communicator foragers ([1, Algorithm 4, Appendix])
For each run:
INITIALIZATION
Initialize grid environment with
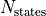 states
statesAdd random food patches to the environment
Initialize foragers:
Assign each forager
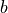 to a random state
to a random state 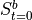 on the grid
on the gridAssign the same values for
 and sight radius to all foragers
and sight radius to all foragers
Initialize a
-length vector 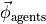 which indicates the number of foragers at each state
which indicates the number of foragers at each state
SIMULATE (
com.SimulateCommunicators)For each frame:
Update rewards at each state based on rate of foragers’ calorie consumption:
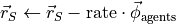
If the total remaining food falls below a threshold, generate additional random food patches
For each forager
:Compute vector
 indicating which states are within this forager’s sight radius (euclidean distance
indicating which states are within this forager’s sight radius (euclidean distance  sight radius)
sight radius)Update expected rewards (food calories) of states within the forager’s sight radius:
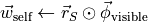
Move forager out of its old state:
![\vec{\phi}_{\text{agents}}[S_t^b] \leftarrow \vec{\phi}_{\text{agents}}[S_t^b] - 1](../../_images/math/1ec91e2ae8f098dae4987f06518a06da244ae99c.png)
Update expected rewards (food calories) for states of other agents:
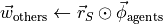
Update this forager’s estimate of the value of each state using reward expectation vectors and Successor Representation matrix:
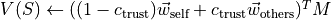
Make a vector containing the values of all states the forager could consider moving to (within the sight radius):
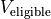
Forager decides its next location:
![S_{t+1}^b \leftarrow \operatorname{argmax}[V_{\text{eligible}}]](../../_images/math/92eae730f4bf4350b29bbb55c14620cfaf93c050.png)
Move forager to its new state:
![\vec{\phi}_{\text{agents}}[S_{t+1}^b] \leftarrow \vec{\phi}_{\text{agents}}[S_{t+1}^b] + 1](../../_images/math/772eab0ca04b4b2cd271024160bd8cf0440e6af9.png)
[3]:
def run_simulations(home_dir, fresh_start=True):
if fresh_start:
start = 0
else:
resultsDF = pd.read_csv(os.path.join(home_dir, "resultsDF.csv"))
start = resultsDF.iloc[-1]["sim index"].astype(
int
) # start with the last existing batch
logging.info(f"Starting from batch {start+1}.")
all_results = []
for si in range(start, N_sims):
# 1. pull out parameters from row si in the metadata
df_row = metadataDF.iloc[[si]]
c_trust = df_row["c_trust"].iloc[0]
sight_radius = df_row["sight_radius"].iloc[0]
reward_patch_dim = df_row["reward_patch_dim"].iloc[0].astype(int)
# arrays to save success measures for each run of this simulation
mean_times_to_first_reward = np.zeros((N_runs))
num_foragers_failed = np.zeros((N_runs))
logging.info(
f"Starting simulation setting {si+1}/{N_sims}, about to run it {N_runs} times."
)
# Do multiple runs of the simulation and store the results in a results dataframe
batch_results = []
for ri in range(N_runs):
# initialize environment
env = com.Environment(
edge_size=edge_size,
N_total_food_units=N_total_food_units,
patch_dim=reward_patch_dim,
)
env.add_food_patches()
# run simulation
sim = com.SimulateCommunicators(
env, N_frames, N_agents, c_trust=c_trust, sight_radius=sight_radius
)
sim.run()
# Compute success measures
time_to_first_allforagers = np.zeros(N_agents)
for forager_id in range(
1, N_agents + 1
): # compute time to first food for each forager
singleforagerDF = sim.all_foragersDF.loc[
sim.all_foragersDF.forager == forager_id
]
time_to_first_allforagers[forager_id - 1] = (
com.compute_time_to_first_reward(
singleforagerDF, sim.all_rewardsDF, N_frames
)
)
mean_times_to_first_reward = np.mean(
time_to_first_allforagers
) # take the average across foragers
num_foragers_failed = np.sum(
time_to_first_allforagers == N_frames
) # number of foragers that failed to reach food
# Save the simulation results in a folder named sim{si}_run{ri} in the home directory
if dev_mode and not smoke_test:
sim_folder = "sim" + str(si) + "_run" + str(ri)
sim_dir = os.path.join(home_dir, sim_folder)
if not os.path.isdir(sim_dir):
os.makedirs(sim_dir)
sim.all_foragersDF.to_csv(os.path.join(sim_dir, "foragerlocsDF.csv"))
sim.all_rewardsDF.to_csv(os.path.join(sim_dir, "rewardlocsDF.csv"))
# Combine the metadata and the success measures for the results dataframe
results_onesim = {
"c_trust": c_trust,
"sight_radius": sight_radius,
"reward_patch_dim": reward_patch_dim,
"sim index": si,
"run index": ri,
"time to first food": mean_times_to_first_reward,
"num foragers failed": num_foragers_failed,
}
batch_results.append(results_onesim)
batch_resultsDF = pd.DataFrame(batch_results)
if "resultsDF" in locals():
resultsDF = pd.concat(
[resultsDF, batch_resultsDF], ignore_index=True, axis=0
)
else:
resultsDF = batch_resultsDF.copy()
if dev_mode and not smoke_test:
resultsDF.to_csv(os.path.join(home_dir, "resultsDF.csv"))
logging.info(f"Saved results for batch {si+1}/{N_sims}.")
run_simulations(home_dir_strong_sim, fresh_start=True)
2024-11-01 09:50:43,962 - Starting simulation setting 1/2, about to run it 1 times.
2024-11-01 09:51:30,410 - Starting simulation setting 2/2, about to run it 1 times.
[4]:
# load the data
def load_communicators(sim_folder):
sim_dir = os.path.join(home_dir_strong_sim, sim_folder)
foragerlocsDF = pd.read_csv(os.path.join(sim_dir, "foragerlocsDF.csv"), index_col=0)
rewardlocsDF = pd.read_csv(os.path.join(sim_dir, "rewardlocsDF.csv"), index_col=0)
# simulation time and grid coordinates start at 1, shift to 0s without modifying the original simulations
foragerlocsDF["forager"] = foragerlocsDF["forager"] - 1
foragerlocsDF["time"] = foragerlocsDF["time"] - 1
rewardlocsDF["time"] = rewardlocsDF["time"] - 1
communicators = ft.dataObject(
foragersDF=foragerlocsDF, rewardsDF=rewardlocsDF, grid_size=35
)
return communicators
noncommunicators = load_communicators("sim0_run0")
communicators = load_communicators("sim1_run0")
To make sure the results make sense, we can animate the run.
[5]:
ft.animate_foragers(
noncommunicators, plot_rewards=True, width=600, height=600, point_size=8
)
[6]:
# animate
ft.animate_foragers(
communicators, plot_rewards=True, width=600, height=600, point_size=8
)
Optional - weak communicators simulation¶
[7]:
# custom list of locations for simulation setup 2
# with focus on low values of c_trust
# the main simulation run is commented out
# uncomment if you want to run many of simulations
min_value = 0.0
max_value = 0.7
density1 = 0.005
density2 = 0.01
c_locations = []
current_value = min_value
while current_value < 0.3:
c_locations.append(current_value)
current_value += density1
while current_value <= max_value:
c_locations.append(current_value)
current_value += density2
# # Simulation setup 2 for the impact of communication
home_dir_weak = os.path.join(
repo_root, "data/foraging/communicators/communicators_weak/"
)
# agent parameters
sight_radius = [5]
c_trust = c_locations
# 0: ignorers,
N_agents = 9
# environment parameters
edge_size = 45
N_total_food_units = 16
reward_patch_dim = [1, 2, 4] # clustered is 4, distributed is 1
# simulation parameters
N_runs = 2 # How many times would you like to run each case?
N_frames = N_frames
# Generate a dataframe containing all possible combinations of the parameter values specified above.
param_list = [i for i in product(c_trust, sight_radius, reward_patch_dim)]
metadataDF = pd.DataFrame(param_list)
metadataDF.columns = ["c_trust", "sight_radius", "reward_patch_dim"]
metadataDF["sim index"] = np.arange(len(metadataDF)).astype(int)
N_sims = len(metadataDF)
# save metadata to home directory
if dev_mode and not smoke_test:
metadataDF.to_csv(os.path.join(home_dir_weak, "metadataDF.csv"))
pd.DataFrame(
[
{
"N_sims": N_sims,
"N_runs": N_runs,
"N_frames": N_frames,
"N_agents": N_agents,
"N_total_food_units": N_total_food_units,
"edge_size": edge_size,
}
]
).to_csv(os.path.join(home_dir_weak, "additional_meta_params.csv"))
display(metadataDF)
print(home_dir_weak)
# uncomment if you want to run 600 simulations
# and turn on dev_mode if you want to overwrite the csvs
# run_simulations(home_dir_weak, fresh_start = True)
| c_trust | sight_radius | reward_patch_dim | sim index | |
|---|---|---|---|---|
| 0 | 0.000 | 5 | 1 | 0 |
| 1 | 0.000 | 5 | 2 | 1 |
| 2 | 0.000 | 5 | 4 | 2 |
| 3 | 0.005 | 5 | 1 | 3 |
| 4 | 0.005 | 5 | 2 | 4 |
| ... | ... | ... | ... | ... |
| 295 | 0.680 | 5 | 2 | 295 |
| 296 | 0.680 | 5 | 4 | 296 |
| 297 | 0.690 | 5 | 1 | 297 |
| 298 | 0.690 | 5 | 2 | 298 |
| 299 | 0.690 | 5 | 4 | 299 |
300 rows × 4 columns
/Users/dima/git/collab2/data/foraging/communicators/communicators_weak/